In March 2026, SadaPay — Pakistan's leading neobank — suffered a full application outage after disruptions hit AWS Bahrain (me-south-1). Funds stayed safe and physical channels (debit cards, ATMs, POS) kept working, but the core app went completely dark for hours.
It's a textbook case study. And it's worth unpacking, because the same failure mode is sitting quietly inside most production systems right now.
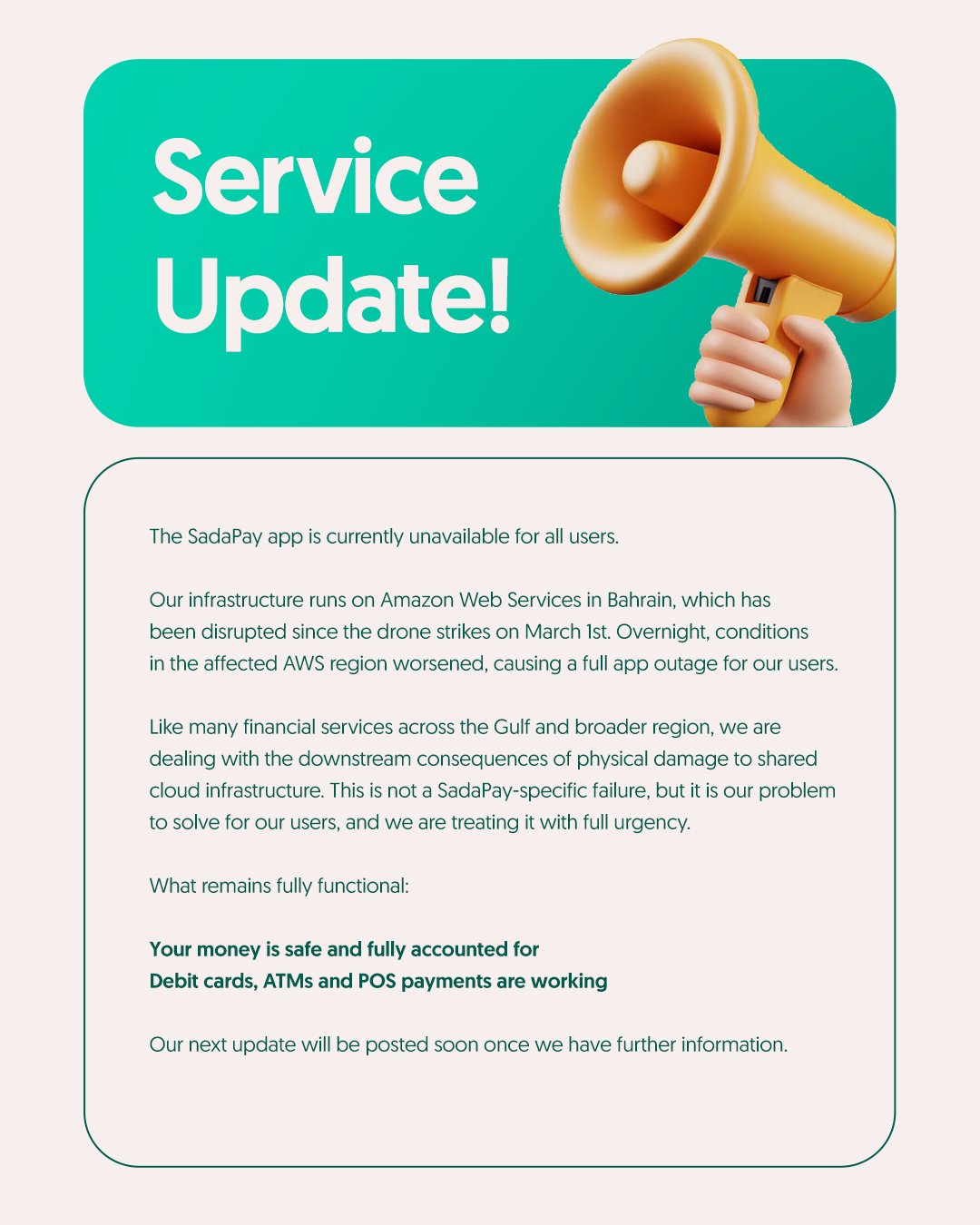
SadaPay acknowledged the outage publicly on X (Twitter), noting the disruption was tied to downstream consequences of physical damage to shared AWS cloud infrastructure.
What Actually Happened
AWS Bahrain experienced regional disruptions that cascaded into SadaPay's infrastructure. Multi-AZ deployments — which protect against a single data center failing — did nothing here, because the problem wasn't one Availability Zone. It was the entire region.
This is the gap between Multi-AZ and Multi-Region, and it catches teams off-guard because Multi-AZ covers 99% of incidents. It's that remaining 1% — a regional event — that turns an inconvenience into a headline.
RTO — How Long Can You Actually Be Down?
Recovery Time Objective is the maximum acceptable time your system can be offline after a failure.
For a neobank, every hour offline is compounding trust damage. Users can't pay bills, transfer money, or check balances. The business impact isn't just lost transactions — it's churn, regulatory scrutiny, and reputation damage that takes months to repair.
RTO forces a critical conversation before an incident: what does downtime actually cost us per hour? That number drives every architecture decision that follows. If the answer is "we can survive 4 hours down", a cold standby in a second region is probably fine. If the answer is "15 minutes", you're building active-active.
RPO — How Much Data Loss Is Acceptable?
Recovery Point Objective is how much data you're willing to lose — measured in time.
For financial transactions: zero. An RPO of even 30 seconds means 30 seconds of transactions potentially unrecoverable. For a bank, that's not a number you can negotiate.
This non-negotiable RPO shapes your entire replication strategy. Synchronous replication to a second region, Aurora Global Database with sub-second replication lag, and careful handling of in-flight transactions aren't nice-to-haves — they're requirements derived directly from RPO.
Multi-AZ vs. Multi-Region — The Critical Difference
These two are often conflated, but they protect against completely different failure modes.
Multi-AZ deploys redundant infrastructure across two or three data centers within the same AWS region. When one data center loses power or networking, traffic automatically fails over to the healthy AZ. This handles the vast majority of AWS incidents — hardware failures, localised networking issues, single-facility events.
Multi-Region deploys a full copy of your application in a separate geographic AWS region. When an entire region experiences disruption — as happened with AWS Bahrain — Multi-AZ alone cannot help. Traffic needs to fail over to a different region entirely.
For a complete Multi-Region setup on AWS:
- Route 53 health checks + failover routing — automatically shifts DNS to the secondary region when the primary stops responding
- Aurora Global Database — replicates with sub-second lag across regions; promotes a secondary cluster to writer in under a minute
- S3 Cross-Region Replication — keeps object storage in sync between regions
- Tested cutover runbooks — the infrastructure is worthless if your team has never actually run a failover drill
"We Have Backups" Is Not a DR Strategy
This is the part that matters.
A backup is a point-in-time copy of your data sitting somewhere. It tells you nothing about how fast you can get back online, who is responsible for triggering the recovery, what systems need to come up in what order, or whether the process actually works under pressure.
A DR strategy is a documented, tested, automated path back to production — with an RTO and RPO your business can actually live with.
The word tested carries the most weight. A runbook that has never been executed in a real (or simulated) failure is a hypothesis, not a strategy. DR drills are the only way to find out whether your recovery time is 20 minutes or 4 hours. You want to find out during a planned exercise at 2 PM on a Tuesday, not during an actual outage at 3 AM.
What Multi-Region Actually Costs
Multi-region architecture is not free, and it's worth being honest about the trade-offs.
Data residency — some regulations require that customer data doesn't leave a specific country or region. Multi-region may conflict with compliance requirements depending on where your secondary region sits.
Replication lag — even with Aurora Global Database's sub-second replication, there is lag. Active-active architectures (where both regions serve live traffic) require careful conflict resolution logic for writes.
Latency — a user in Karachi hitting infrastructure in an Irish secondary region will notice the difference.
Cost — running two full regions costs roughly double the infrastructure. For early-stage products, the right answer might be a warm standby rather than a full active-passive setup.
None of this means "don't do Multi-Region." It means the architecture decision should be driven by your actual RTO and RPO requirements, not by a vague sense that redundancy is good.
The Takeaway
Architecture decisions made at day one determine whether your team is sleeping or firefighting at 3 AM when a region goes dark.
For a regulated fintech operating at scale, Multi-Region isn't optional — it's a product requirement. The SadaPay outage is a reminder that even well-run engineering teams on solid cloud infrastructure can get caught by regional events, and the only real protection is designing for that scenario before it happens.
Define your RTO and RPO. Build to them. Test them. Then test them again.